云计算架构下Cloud TiDB的技术奥秘(上) 架构演进与核心优势
在当今数字化转型的浪潮中,数据库作为承载核心业务数据的基石,其技术架构的演进直接关系到企业的敏捷性与竞争力。传统集中式数据库在应对海量数据、高并发访问及弹性扩展需求时,常显得力不从心。而云计算与分布式技术的融合,为数据库领域带来了革命性的变化。Cloud TiDB,作为一款诞生于云原生时代的分布式关系型数据库,正是这一变革的杰出代表。它并非简单地将TiDB部署在云上,而是深度整合了云计算的弹性、服务化与自动化特性,形成了独特的“云计算装备技术服务”体系。
一、 云原生分布式架构的基石
Cloud TiDB的技术奥秘,首先根植于其纯正的云原生与分布式基因。其架构核心继承了TiDB开源项目的精华,并针对云环境进行了深度优化与重构。
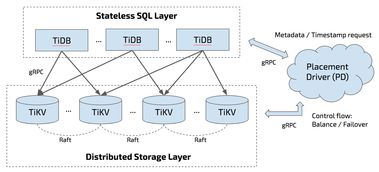
- 计算与存储分离的弹性设计:这是Cloud TiDB架构的“第一性原理”。它将计算层(TiDB Server,负责SQL解析、优化与执行)与存储层(TiKV,负责数据持久化与分布式事务)彻底解耦。这种分离带来了前所未有的灵活性:
- 独立扩展:计算资源可以根据业务查询压力独立伸缩,存储资源可以根据数据量独立扩容,互不干扰,资源利用率最大化。
- 快速弹性:在云计算平台上,可以借助虚拟化与容器技术,实现分钟级甚至秒级的节点扩缩容,完美应对突发流量与周期性业务高峰。
- 成本优化:用户可以为计算和存储分别选择最适合的实例类型与计费模式,例如为计算层选择高性能CPU实例应对复杂查询,为存储层选择高容量低成本实例存储海量数据。
- 多层次的高可用与容灾:Cloud TiDB将高可用能力构建在架构的每一个层级。
- 节点级:计算与存储节点均采用多副本(通常为3副本)机制,基于Raft共识协议确保数据强一致。任何单节点或甚至少数节点故障,集群都能自动进行故障转移与数据恢复,业务无感知。
- 可用区级:在云环境中,可以将集群的不同副本跨多个可用区(AZ)部署,实现机房级别的容灾,抵御数据中心级别的故障。
- 地域级:通过异步或同步(取决于对RPO/RTO的要求)的数据同步技术,可以构建跨地域的容灾备份,满足最高级别的业务连续性要求。
二、 作为“云计算装备”的核心技术服务
Cloud TiDB的“云服务化”特性,使其从一款数据库软件,升华为一套开箱即用、按需取用的“技术服务装备”。
- 全托管的服务体验:用户无需关心底层基础设施的 provisioning、安装部署、版本升级、安全补丁、备份恢复等复杂且耗时的运维工作。云服务商提供全生命周期的自动化管理,将DBA从繁重的日常运维中解放出来,使其能更专注于数据价值挖掘与业务创新。这本质上是将专业的数据库运维能力,以服务的形式交付给客户。
- 无缝的生态集成:作为云平台上的“一等公民”,Cloud TiDB能够与云上的其他服务无缝集成,形成强大的合力。
- 与对象存储集成:自动将备份数据存储到如Amazon S3、Google Cloud Storage或阿里云OSS等低成本、高持久性的对象存储中,保障数据安全。
- 与监控告警服务集成:原生对接云监控平台,提供数百项关键指标(如QPS、延迟、节点状态、存储容量等)的实时监控与智能化告警。
- 与网络与安全服务集成:轻松配置私有网络(VPC)、安全组、SSL加密传输,并与云平台的身份访问管理(IAM)服务打通,实现细粒度的权限控制。
- 极致的弹性伸缩服务:这是Cloud TiDB作为云计算装备最直观的技术体现。除了手动调整节点规模外,更支持基于预设规则的自动弹性伸缩策略。例如,可以设置当CPU利用率持续5分钟高于70%时,自动增加一个计算节点;当业务低谷期流量下降时,自动缩减资源。这种“用时付费,按需扩展”的模式,使得企业能够以最优的成本应对业务的不确定性。
(上篇小结)
Cloud TiDB在云计算架构下的首要技术奥秘,在于其通过计算存储分离的云原生架构,构建了极致的弹性与韧性基础;并通过全托管、深度集成、弹性伸缩等“技术服务化”手段,将复杂的分布式数据库能力封装成易于消费的“云计算装备”。这解决了企业自建分布式数据库技术门槛高、运维成本巨大的核心痛点。
在下篇中,我们将深入探讨Cloud TiDB在具体技术实现上的奥秘,包括其如何保证分布式事务的强一致性(如Percolator模型的应用)、如何实现与MySQL的高度兼容以降低迁移成本、以及智能优化器如何在大数据量下保障查询性能等更深层次的技术细节,敬请期待。
如若转载,请注明出处:http://www.rxinyun.com/product/13.html
更新时间:2026-06-19 01:36:22